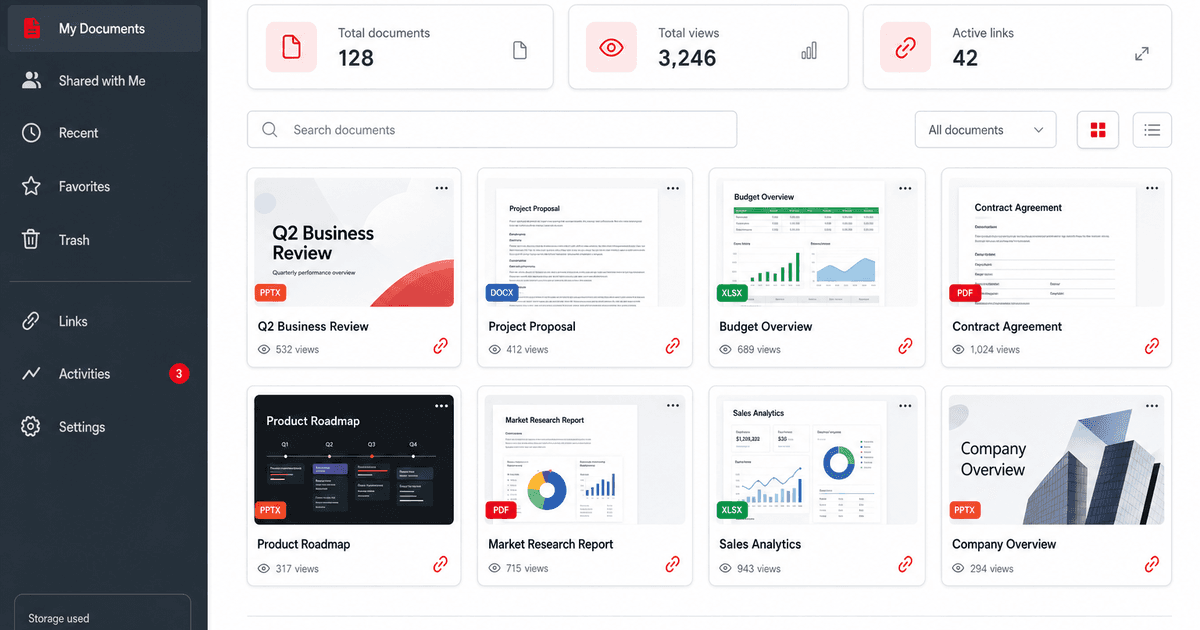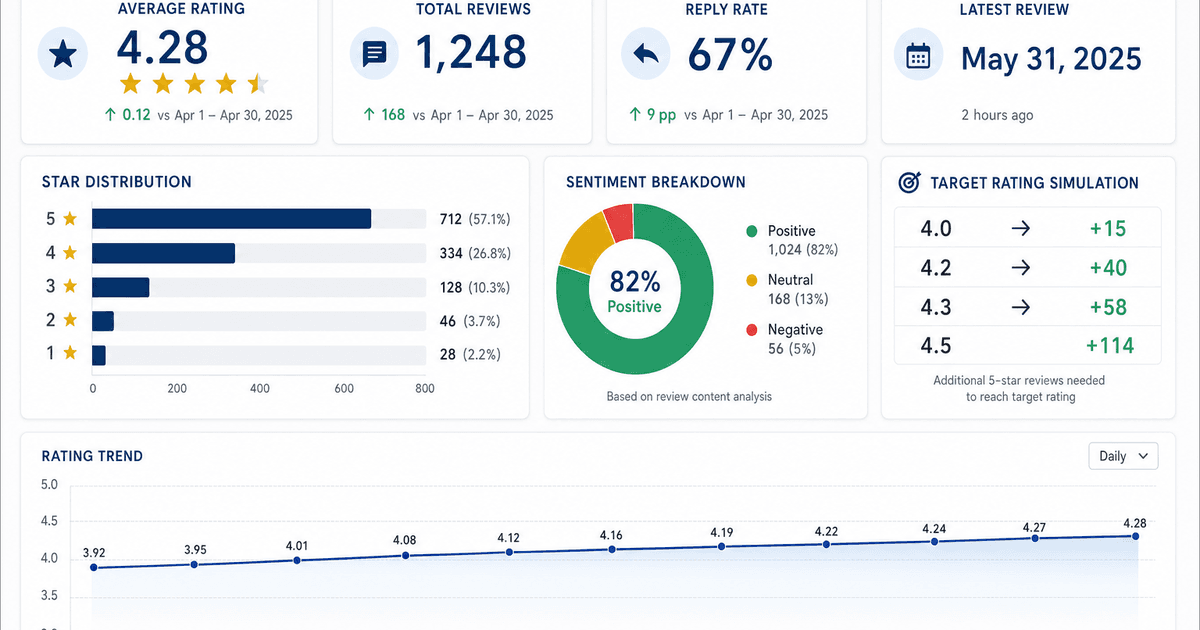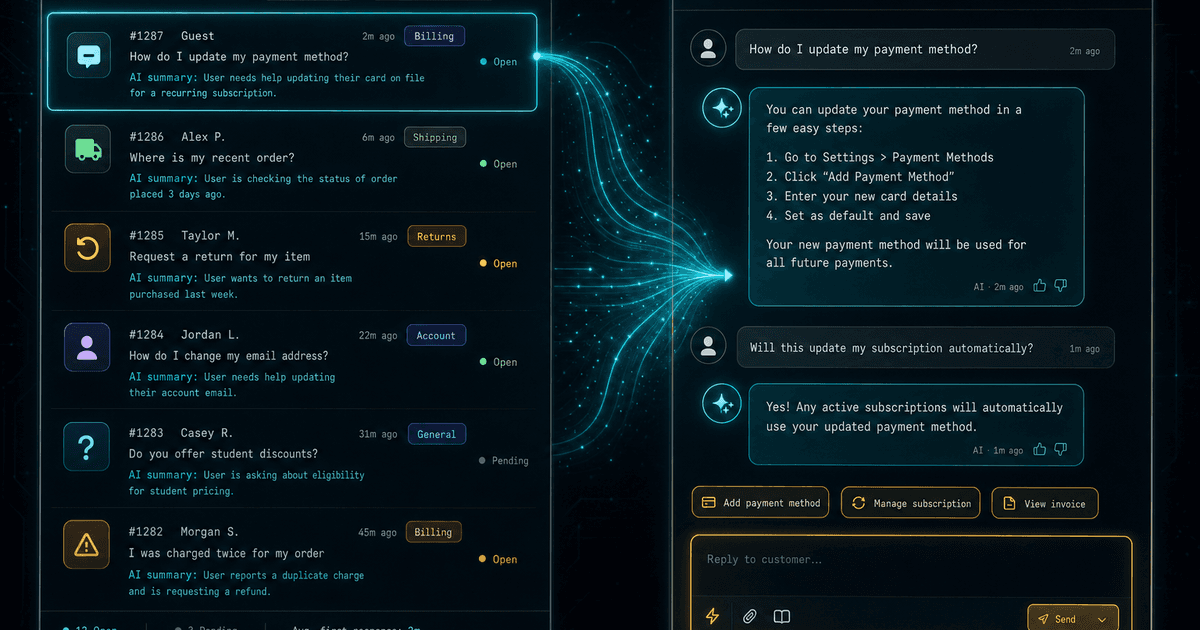
Latest · 最新記事
「どのモデルが最強か」はもう古い ──Sakana Fuguが見せた、AIを束ねる”司令塔”の競争
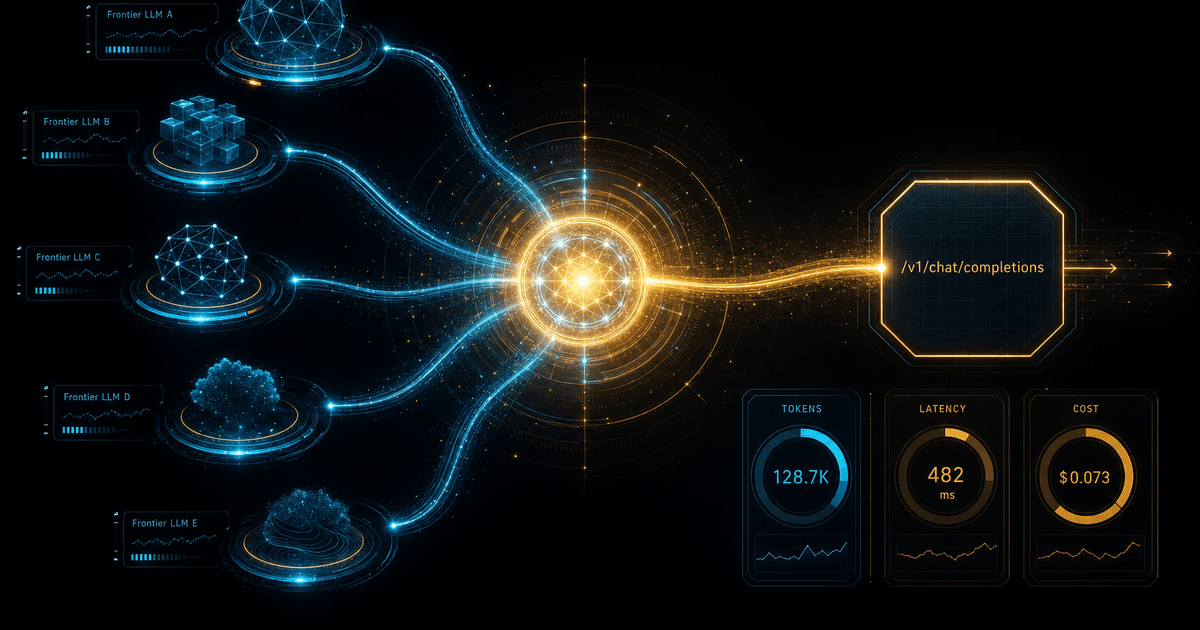
「GPT・Claude・Geminiどれが最強か」はそろそろ古くなる。Sakana AIが2026-06-22にGA公開したFugu / Fugu Ultraが面白いのは、新しい巨大モデルを作ったからでなく、複数の強いモデルをどう呼び分け協調させるかを“モデルそのもの”にした点だ。モデル選択・役割分担・検証・やり直しを、外側のコードでなく学習済みの司令塔(coordinator)へ寄せる。OpenAI互換APIでbase_url/modelの差し替えで試せ、Codex CLIにはcodex-fuguラッパー。ルーターでもMixtureでもなく、TRINITY/Conductor基盤で役割(Thinker/Worker/Verifier)と協調・自己再帰を学習。ただし第三者初日検証では、軽いコード生成でfugu 55秒/2,141トークン vs fugu-ultra 269秒/28,950トークン(司令塔トークン込み)で品質差は限定的=軽い仕事にUltra常用は割に合わない。司令塔トークンは可視だがモデル別呼び出しは見えず監査に不足しうる。導入軸はquality/latency/cost/traceability/governance、置き換えでなくadvisor/fallback/benchmarkとして測ってから。数値は各社公式主張/初日小サンプルでCAG非検証。