技術ノート | AIの最新動向を、現場目線で
AIエージェントを毎日の仕事で使い始めると、すぐに同じ壁に当たる。モデルはどんどん賢くなる。コードも書ける、調査もできる、議事録も要約する。なのに、実際の仕事で使えるかどうかは、モデルの賢さだけでは決まらない。
その仕事の前提を知っているか。過去に何を決めたかを読めるか。どのファイルを正本として扱うべきか。どの判断はもう古いのか。──結局、AIに足りないのは「長いプロンプト」ではなく、毎回ゼロから説明しなくても読める"引き継げる知識"だ。
2026年、Google Cloud が公開した Open Knowledge Format(OKF) は、この感覚にはっきりした名前を与えた。[1] 私たち電脳技巧集団(AI職人ギルド)は、人間とAIが共同編集するMarkdownの知識ベースを日々運用している。だからOKFを、流行語ではなく「で、知識の持ち方はどう変わるのか」という現場目線で読み、自分たちの運用を一次情報として確かめた。なお外部仕様はCAGの検証ではなく公式発表に基づく。
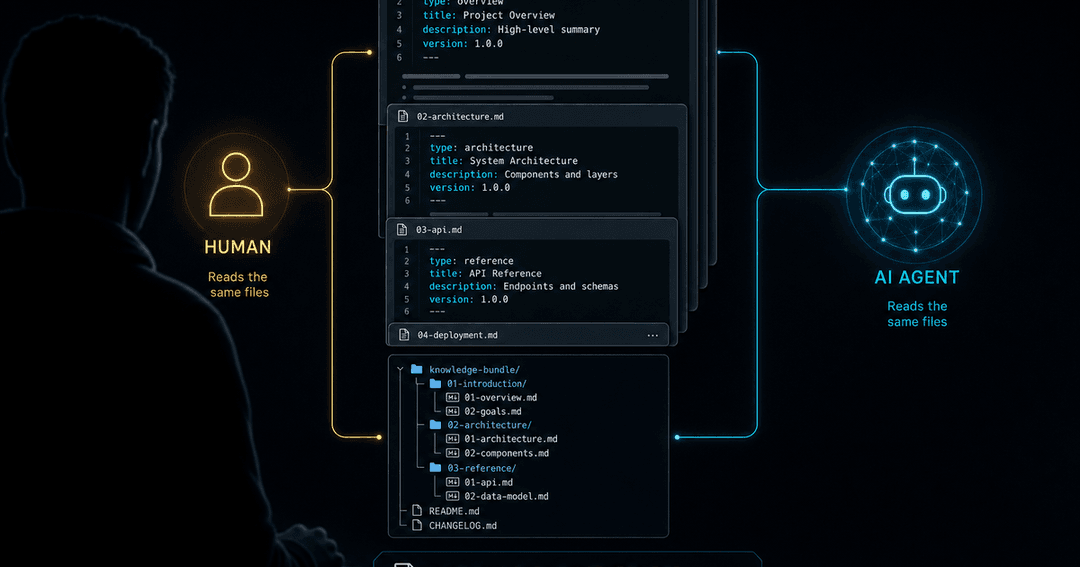
01AIに足りないのは「賢さ」ではなく「引き継げる知識」
新しいセッションを開くたびに、私たちは同じ説明を繰り返してきた。「このプロジェクトはこういう前提で」「この値が正本で」「あの判断はもう古いから無視して」。モデルが賢くなっても、文脈を毎回貼り直す消耗は消えない。
本当に必要なのは、AIが作業を始める前に自分で読みに行ける"知識の置き場"だ。前回までに決めたこと、正本のありか、やってはいけないこと、誰のためのプロジェクトか。これが整っていれば、AIは「賢い新人」から「文脈を分かっている同僚」に変わる。OKFは、その置き場をどんな形で持つべきかという問いに、ひとつの答えを出した。
02OKFとは何か ──Markdownの知識bundleに名前がついた
Open Knowledge Format v0.1 は、知識をMarkdownファイルと YAML frontmatter のディレクトリ構造として表現するための仕様だ。[1][3] 新しいSaaSでも、専用DBでも、独自ランタイムでもない。人間が読めて、AIエージェントも読めて、gitで差分管理できる──そういう知識の"束"である。
conceptごとに1つのMarkdownを置く。先頭の frontmatter に type や title、description、tags、timestamp といった最小限の構造化情報を書き、本文にはスキーマ・例・手順・背景を書く。リンクは普通のMarkdownリンクで張る。vendor-neutral(特定のagent・framework・モデル提供者に縛られない)を掲げているのが肝だ。[2]
一点だけ、面白い注記がある。仕様(SPEC)上の必須frontmatterは type ひとつだけ。だがGoogleのリファレンス実装では type / title / description / timestamp の4つが必須扱いになっている。[3][4] 仕様と実装でズレがある──まだv0.1のDraftだという証拠でもあり、後で効いてくる伏線でもある。
03なぜ「サービス」でなく「フォーマット」なのか
OKFで一番うなずいたのは、Google Cloudの記事が「必要なのは、もうひとつの知識管理サービスではなく、フォーマットだ」と言っていることだ。[1] ここがこの話の芯だと思う。
いまの組織の知識は、とにかく散らばっている。データカタログ、Notion、Google Docs、Slack、コードコメント、スプレッドシート、そして古参メンバーの頭の中。AIに「週次のアクティブユーザーはどう数える?」と聞いても、その答えに必要な文脈は複数の場所に分かれていて、しかも各ツールは違うAPI・違う権限・違う表現形式を持つ。新しいSaaSをもう1つ足しても、断片がもう1つ増えるだけだ。
OKFはこの断片を、まずファイルに戻す。データカタログだけでなく、API・指標(Metric)・手順書(Playbook/Runbook)・参照資料(Reference)のような概念にも同じ形を当てられる。[3] 「どのツールに保存するか」の前に、「どの形式なら誰でも・何でも読めるか」を先に決める、という発想の転換だ。
04私たちのWikiは、すでにこの形だった
ここからは外の仕様の話ではなく、私たちの一次情報だ。OKFを読んで最初に感じたのは「これ、ずっとやってきたことだ」だった。
私たちは、プロジェクト・開発知見・調査メモ・人物・ゴール・Journey(制作の記録)を、すべてMarkdownで管理するナレッジベースを運用している。frontmatterには category / tags / sources / created / updated / status を持たせ、ページ同士はリンクで結ぶ。人間がエディタで読めるし、CodexやClaude Codeのようなエージェントも、作業の前にこの文脈を参照する。人間が読むWikiでありながら、AIが作業前に読む文脈でもある。記事も製品も、この知識の上で回している。
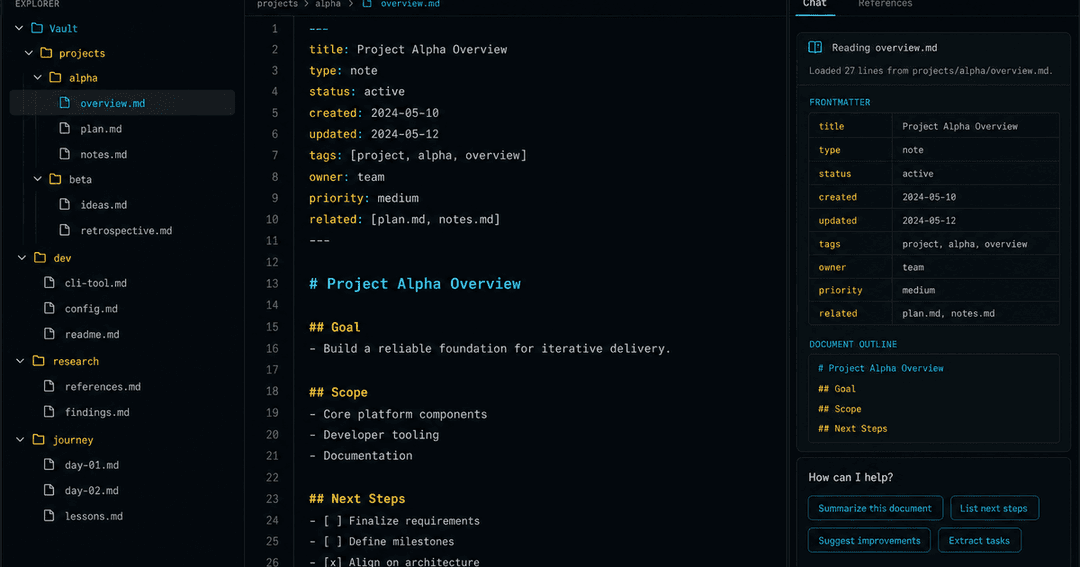
だからOKFは、私たちにとって「自分たちのやり方に、業界の共通語がついた」という感触に近い。AndrejKarpathyが提唱した「LLM Wiki」の発想とも地続きで、その延長線上にある考え方だ。[5] このナレッジベースをどう設計してきたかは、別の連載で詳しく書いている。
 関連記事 | この知識ベースの作り方【AIと"第二の脳"を作る #1】なぜ"普通のメモアプリ"は続かないのか──8つのPKM挫折と「LLM Wiki」という解
→
関連記事 | この知識ベースの作り方【AIと"第二の脳"を作る #1】なぜ"普通のメモアプリ"は続かないのか──8つのPKM挫折と「LLM Wiki」という解
→
05そのまま移行はしない ──正本を壊さず"export"で繋ぐ
ただし、ここで雑に「全部OKFに移行しよう」と考えるのは危険だ。私たちのナレッジベースはObsidianと、人間×LLMの共同編集に最適化されている。[[dev/foo]] 形式のwikilink、ゴールの記法、Daily、raw、logs、Journeyといった独自の運用ルールがある。一方OKFには、index.md や log.md の扱い、concept documentに必須の type、そして前述の「SPECより厳しいリファレンス実装のrequired」がある。[4] 正本どうしの最適化先が違うのだ。
だから正しい接続は「正本を壊す」ことではなく、OKF互換の"export(書き出し)"を作ることだと考えている。正本はObsidian向けのまま運用し、AIに渡すときだけOKF形式に変換する層を挟む。
実際に今回、私たちのナレッジベース側に「OKF互換ページ」を1枚作り、既存のfrontmatter(category / sources / created / updated / status)を維持したまま、OKF互換の type / description / resource / timestamp / okf_version を同居させた。これならObsidian側の運用を壊さず、OKF consumerにも意味が通る。「正本は人間最適、書き出しはAI最適」の二段構えだ。
06これは個人の話で終わらない ──企業ナレッジを"AIが読める"形に
この話は、個人のメモ術で終わらない。企業の業務ナレッジこそ、いずれ「人間が読むマニュアル」だけでは足りなくなる。
AIエージェントに、予約システムの仕様を読ませる。問い合わせ対応の手順を読ませる。過去の意思決定や、営業資料の前提を読ませる。そのとき、ナレッジがGoogle DocsやNotionの奥に閉じているより、agent-readyな束として整理されている方が圧倒的に強い。私たちが支援先の業務ナレッジを扱うときも、同じ設計判断が効く。
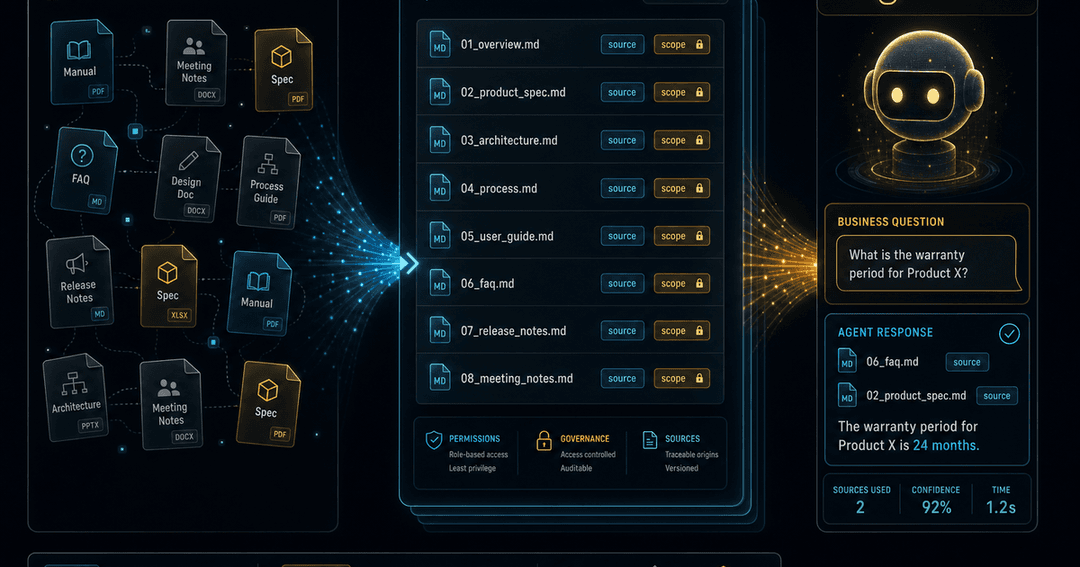
つまりAI導入支援の本体は、モデル比較から「知識をどう整えるか」へ移っていく。企業に本当に必要なのは、単にChatGPTを配ることではない。社内の業務知識を、AIが読める形に直し、更新される仕組みを作り、権限と出典を管理することだ。OKFは、その共通言語の候補になり得る。私たちが日々ナレッジベースでやっていることを、お客さまの業務の上に組み直す——ここに私たちの仕事がある。
07締め:「どこに書くか」から「どう引き継げるか」へ
最後に、煽りすぎないよう釘を刺す。OKFはまだv0.1のDraftだ。[3] Google Cloud以外の広い採用はまだ確認できていないし、仕様と実装でrequiredの扱いも揺れている。標準になるかどうかは、これからの採用次第だ。
もう一つ大事な釘。OKF化は、知識の質を自動では上げない。 古い情報、根拠不明、重複、権限の問題は、形式を変えても残る。むしろ企業ナレッジをagent-readyにするなら、機密情報・顧客情報・社内権限を分ける設計(レーン分け)が前提になる。「形式が整う」と「中身が正しく・安全に運用できる」は別問題だ。
それでも、方向性はかなり明確だ。AIエージェント時代の知識管理は、「どのツールに書くか」から「どの形式で引き継げるか」へ移る。人間が読むWikiから、AIが引き継ぐKnowledge Bundleへ。電脳技巧集団(AI職人ギルド)は、最新のAIを使いこなすと同時に、その土台になる知識を"引き継げる資産"として設計することを本業にしている。OKFは、その転換点のひとつとして見る価値がある。
「どこに書くか」から「どう引き継げるか」へ。この変化を、一枚に。
| 観点 | ツールに閉じた知識管理 | 引き継げる知識(OKF的bundle) |
|---|---|---|
| 置き場 | Notion / Docs / 各SaaSの奥 | Markdownファイル+git |
| 読み手 | 人間だけ(UI前提) | 人間もAIも同じファイル |
| 構造 | ツール独自・取り出しにくい | frontmatterで最小構造化・vendor-neutral |
| AIへの渡し方 | 毎回プロンプトで貼る | 束ごと読ませる(agent-ready) |
| 移行性 | ベンダーロック | gitで持ち運べる |
| 正本との関係 | そのツールが正本 | 正本は維持しexportで両立 |
※ 本記事はGoogle Cloud等の公式発表・公開仕様を、開発実務の観点から整理・論評したもの。OKFの仕様・実装に関する事実は下記出典に基づく引用であり、CAG自身が標準化や採用状況を検証したものではない(v0.1 Draft・2026-06時点)。私たちのナレッジベース運用とOKF互換ページの実例は自社の一次情報。状況は流動的で、仕様は更新されうる。
脚注・出典
- Google Cloud Blog「How the Open Knowledge Format can improve data sharing」。OKF v0.1 の提案と「必要なのはサービスでなくフォーマット」という主張。cloud.google.com/blog
- OKF GitHub(GoogleCloudPlatform/knowledge-catalog/okf)。spec・samples・reference enrichment agent・visualizerを含む。vendor-neutralをREADMEで明示。github.com/GoogleCloudPlatform/knowledge-catalog
- OKF SPEC.md。Markdown+YAML frontmatter+directory tree。SPEC上の必須frontmatterは
typeのみ(title/description/resource/tags/timestamp はrecommended/optional)。SPEC.md - OKF reference implementation(
okf/src/enrichment_agent/bundle/document.py)。実装ではtype/title/description/timestampの4つがrequired扱い(SPECとの差)。document.py - Andrej Karpathy「LLM Wiki」gist。MarkdownをLLMの文脈として読む発想。OKFはこの流れの延長線上にある(本記事の整理)。gist.github.com/karpathy
その業務知識、AIが読める形になっていますか?
社内に散らばったマニュアル・仕様・意思決定を、人もAIも引き継げる"知識の束"へ。整え方・更新の仕組み・権限と出典の管理まで設計します。まずは相談から──問い合わせは、AIがその場でお応えします。
無料で相談する →