


気になるAIの話を、分かりやすく | 最新動向を、現場目線で
「AIを全社導入すれば生産性が上がる」。この話は、もう半分正しくて、半分古い。2026年に入って見え始めたのは、AIを使える会社ほど、次はAIの"使いすぎ"に悩むという現実だ。
問題は社員が怠けていることではない。AIエージェントが進化して、1回の作業が「短い質問」ではなくなった。リポジトリを読む。ログを読む。何度も試す。長い説明を書く。失敗したらやり直す。そのすべてがトークンとして請求に積み上がる。
これは「AIは高すぎるから終わり」という話ではない。むしろ逆で、実験の段階から、運用の段階へ移ったサインだ。今日はその変化を、GitHub・OpenAI・Anthropicの公式ドキュメントと最近の報道をもとに、分かりやすく整理してみる。私たち電脳技巧集団(AI職人ギルド)も毎日AIエージェントで開発している側なので、その現場目線で見ていく。
01なぜ「AIを使わせながら制限する」会社が増えたのか
2026年7月初め、404 Mediaが「企業が社員のAI利用を絞り始めている」と報じた。公開された範囲では、複数の業界でAI利用に上限を設けたり、無制限だった高性能モデルのアクセスを終了したり、月に数百万ドル規模まで膨らんだAI支出の例が挙げられている[1](※内部資料ベースの報道で、個別企業の数字はそのまま検証できない部分もある)。
見出しだけ読むと「やっぱりAIは高すぎたのか」と受け取りたくなる。でも、各社の公式ドキュメントを見ると、話はもっと落ち着いている。撤退しているのではなく、予算管理・モデルの使い分け・使用量の可視化を整え始めている。つまり「使うか・使わないか」から「どう運用するか」へフェーズが移った。この記事は、その"運用"の中身を分解していく。
02Copilotの「使った分だけ課金」への転換が示すもの
いちばん分かりやすい変化が、GitHub Copilotだ。GitHubは2026-04-27に、Copilotを使用量ベースの課金(usage-based billing)へ移すと発表し、2026-06-01から適用した[2]。
これまでの「プレミアムリクエスト◯回まで」という数え方から、AI Credits という単位に変わった。1 AI Credit=$0.01で、入力トークン・出力トークン・キャッシュされたトークンを、モデルごとの単価でクレジットに換算する[3]。BusinessやEnterpriseでは、クレジットが組織で共有プールになる(例:100人のBusinessなら共有プール190,000 AI credits。既存顧客には2026-06-01〜09-01の3か月、移行用のクレジットが付く)[3]。
なぜ変えたのか。GitHubの説明はシンプルで、Copilotが「チャットで聞く道具」から「自律的に作業するエージェント」へ変わり、短い質問と、数十分かけてリポジトリを読み込むエージェント作業を、同じ"1回"で数えるのが持続しなくなったからだ。使う仕事の重さが桁違いに広がったので、実際の消費量で課金するほうが素直、という判断だ。
03AIエージェントは、なぜトークンを食うのか
ここが今日の肝だ。同じ「AIに頼む」でも、チャットの一問一答とエージェント作業では、消費するトークンの量がまるで違う。エージェントの1タスクは、だいたいこう積み上がる。
- 入力(読む):リポジトリのコード、長いログ、ツールの出力、過去の会話履歴。文脈が大きいほど、毎ターンの入力が膨らむ。
- 推論(考える):高性能モデルほど、内部で長く"考える"(reasoning)。その思考もトークンとして乗る。
- 出力(書く):長い説明・大きな差分・複数ファイルの生成。
- やり直し(loop):失敗して試行を繰り返すたびに、上の全部がもう一度乗る。失敗したエージェントのループは、そのまま請求に跳ねる。
だから「安いモデルに替える」だけでは足りない。入力に何を渡すか、どのモデルに投げるか、どこで人間が止めるかを設計しないと、定額に見えるUIの裏で消費が静かに膨らむ。ここが、次に効いてくる運用ポイントになる。
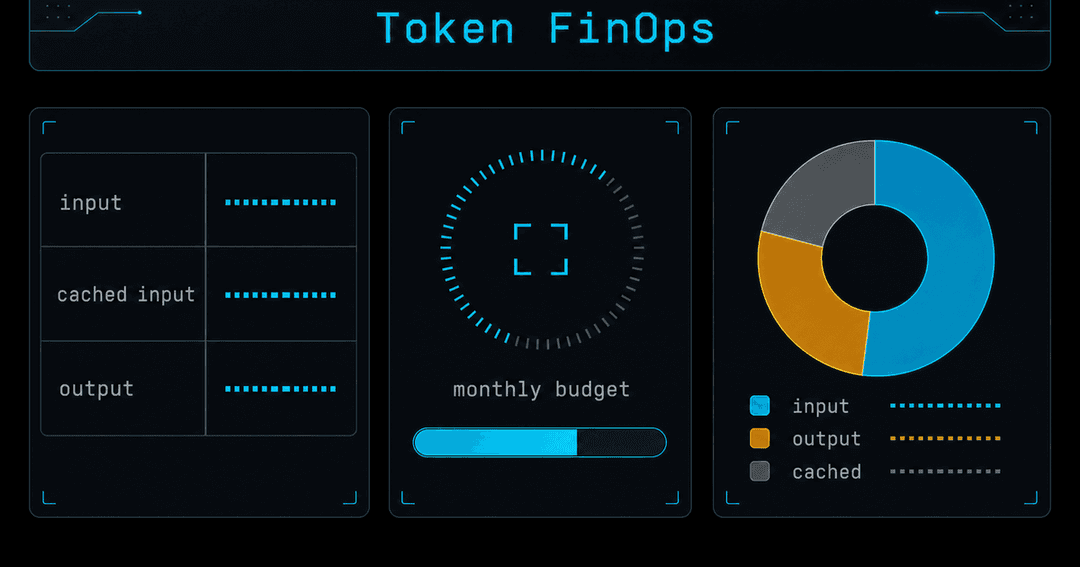
04各社の公式機能は「トークンFinOps」へ向かっている
面白いのは、GitHub・OpenAI・Anthropicが、開発者が原価を直接扱うための機能を、そろって公式に用意し始めていることだ。まるで会計(FinOps)の道具立てがAIに移ってきたようになっている。
- GitHub:ユーザー単位・組織単位・エンタープライズ単位の予算コントロール。ユーザー単位の予算は上限で止まる(hard stop)、組織/エンタープライズ単位はプール枯渇後の追加課金を制限する、と使い分けが説明されている[4]。
- OpenAI:モデル階層ごとに入力・キャッシュ入力・出力の価格が大きく違う。プロンプトキャッシュを使うと、共通の前置き(system promptなど)を再利用してレイテンシと入力コストを下げられる(docsは最大でレイテンシ約80%・入力トークンコスト約90%削減と説明)[5]。ただしプロジェクトの予算(budget)は"soft alert"で、超過しても自動では止まらない点は要注意——止めたいなら別の仕組みが要る[6]。
- Anthropic:モデル・キャッシュ・出力で価格が分かれ、トークンカウントAPIで事前に見積もれる。Claude Codeには使用量の可視化があり、公式ドキュメントは企業導入の平均を1人あたり1稼働日 約$13/月 約$150〜250と目安として挙げている(あくまで平均で、チームにより大きく変わる)[7]。
共通しているのは、「使わせない」ではなく「見えるようにして、設計で抑える」方向だ。
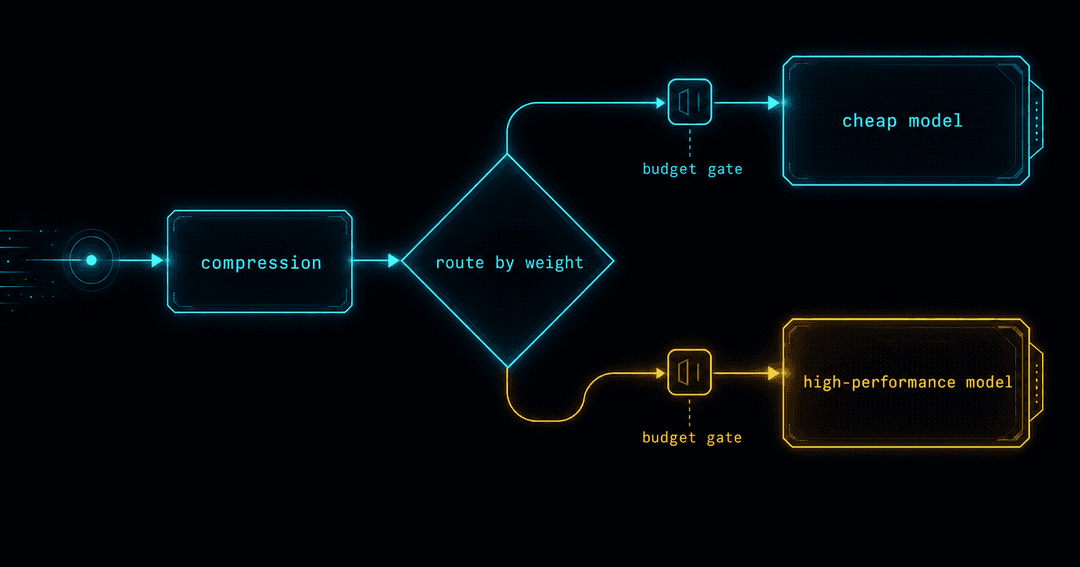
05「読ませる前に設計する」──圧縮・キャッシュ・ルーティング
もうひとつの動きが、エージェントに読ませる前に文脈を減らすツールの登場だ。GitHubで急速に伸びている headroom は、ツールの出力・ログ・検索チャンク・ファイル・会話履歴を、LLMに届く前に圧縮する層で、ライブラリ/プロキシ/MCPサーバー/エージェントのラッパーとして使える[8](リポジトリは60〜95%のトークン削減を掲げるが、これはREADME上の主張で、実環境での再現検証は別途必要)。
大事なのは、これを「ただの節約ツール」と見ないことだ。圧縮は入力設計であって、削りすぎるとエージェントが必要な証拠を読めなくなり、トークンは減っても品質や安全性が落ちる。だから「元の情報に戻せる(reversible)検索」「圧縮前後の品質比較」「監査ログ」とセットで考える。この「AIに余計なものを読ませない・書かせない」という発想は、以前CAGが書いた記事とまっすぐつながっている。
 関連記事 | 無駄を書かせない設計「たくさん書けるAI」から「無駄を書かないAI」へ ──Agent Minimalism、上手さはAIに余計な仕事をさせないことへ
→
関連記事 | 無駄を書かせない設計「たくさん書けるAI」から「無駄を書かないAI」へ ──Agent Minimalism、上手さはAIに余計な仕事をさせないことへ
→
実務に落とすと、効く手はだいたい4つだ。
- モデルのルーティング:全部を最高モデルに投げない。分類・要約・軽微な修正・検索は安い/速いモデル、設計判断・セキュリティ・難しいデバッグだけ高性能モデルへ。
- プロンプトキャッシュ:共通のsystem promptや
AGENTS.md、静的な文脈は先頭に、変わる部分は末尾に置く。コストにもレイテンシにも効く。 - 圧縮とretrieval:大きなログや履歴は、丸ごと読ませず、要約・索引・圧縮を挟む。
- 予算ゲートと人間承認:月次上限、重いタスクの事前承認、失敗ループの打ち切り、フォールバックモデル。
CAG(電脳技巧集団)でも、AIエージェントで開発するときは「どの仕事にどのモデルを使い、何を文脈に渡し、どこで人が止めるか」を先に決めておく。派手さはないが、これがそのまま毎月のコストと品質を左右する。
06まとめ ──AIを「使える」会社から、「運用できる」会社へ
AI活用が進んだ会社ほど、次に必要になるのは「もっと良いプロンプト」ではなく、AIの原価管理だ。そしてAIエージェント時代の原価管理は、単なる節約ではない。どの仕事に強いモデルを使い、どの文脈をキャッシュし、どの情報を圧縮し、どこで人間が止めるかを設計することだ。
怖がる必要はない。トークンの消費は、可視化して、使い分けて、設計すれば十分にコントロールできる。各社の公式機能も、その方向に急速にそろってきている。「AIは高すぎる」で止まるのではなく、「使いすぎても破綻しない運用」を作れるかどうか。そこが、AIを"使える"会社と"運用できる"会社の分かれ目になる。
プロンプト術の次は、トークン経済(token economics)。地味だが、ここを設計できる会社が、AIを長く回し続けられる。
同じ「AIを使う」でも、定額として見るか、運用設計するかで、来月の請求も品質も変わる。今日の要点を一枚に。
| 観点 | "定額で使わせる"(旧) | "運用設計して使う"(今) |
|---|---|---|
| コストの見方 | 月額料金 | 読ませた文脈・書かせた出力・やり直し回数 |
| 課金単位 | 1リクエスト | 入力/出力/キャッシュ トークン × モデル単価 |
| モデル選択 | 全部いちばん賢いモデル | 仕事の重さでルーティング |
| 文脈 | 丸ごと読ませる | 圧縮・キャッシュ・retrieval |
| 予算 | 気づいたら超過 | 月次上限・重いタスクは承認 |
| 失敗ループ | そのまま請求に | 打ち切り・フォールバック |
| 何が差になるか | 良いプロンプト | トークン会計・入力設計 |
※ 本記事はGitHub・OpenAI・Anthropic の公式ドキュメントおよび404 Media等の報道を、AIを業務に使う側の観点から分かりやすく整理したもの。価格・クレジット・平均コスト・削減率などの数値はすべて公式・報道・GitHub上の主張の引用であり、CAG自身の検証結果ではない。数値は2026-07-05時点の公開値で変動しうる(v0)。企業のAI利用制限報道は一部会員限定・内部資料ベースのため個別数字は慎重に扱う。
脚注・出典
- 404 Media「Companies Are Throttling Employees' AI Use Because It's Too Expensive」。高コストモデルの制限・無制限アクセス終了・使用量監視への移行という報道。内部資料ベースで個別数字は全量検証不可。404media.co
- GitHub Blog「GitHub Copilot is moving to usage-based billing」(2026-04-27発表・2026-06-01適用)。agentic化でinference需要が増え、旧premium request modelが持続しないと説明。github.blog
- GitHub Docs「Models and pricing」「Usage-based billing for organizations and enterprises」。1 AI Credit=$0.01、input/output/cached tokensをモデル別に価格化。Business/Enterpriseは共有プール(例100人=190,000 credits)、既存顧客に2026-06-01〜09-01の移行クレジット。docs.github.com
- GitHub Docs「Budgets for usage-based billing」。user単位=hard stop、cost center/enterprise単位=プール枯渇後のmetered charges制限。docs.github.com
- OpenAI API Docs「Pricing」「Prompt caching」。モデル階層で入力/キャッシュ入力/出力の価格差。prompt cachingは共通prefix設計で最大レイテンシ約80%・入力コスト約90%削減。価格は変動、確認時点必須。developers.openai.com
- OpenAI Help Center「Managing your work in the API platform with Projects」。monthly budgetはsoft spending threshold=超過してもAPIリクエストは処理される(自動停止ではない)。hard capが要るなら別レイヤー。help.openai.com
- Anthropic Docs「Pricing」「Claude Code costs」「Token counting」。モデル・cache・outputで価格分離、token countingで事前見積り。Claude Code企業導入の平均目安 1人1稼働日 約$13/月 約$150〜250(平均値・チームにより変動)。docs.anthropic.com
headroomlabs-ai/headroom(GitHub・Apache-2.0)。ツール出力/ログ/RAGチャンク/ファイル/会話履歴をLLM到達前に圧縮、library/proxy/MCP/agent wrap/reversible retrievalを提供。60〜95%削減はREADMEの主張で実環境検証が必要。数値は2026-07-05時点。github.com/headroomlabs-ai/headroom
「AIを入れたら、来月いくら請求される?」——その原価設計、一緒にやります。
モデルの使い分け・月次上限・使用量の可視化・圧縮・人間承認まで含めて、使いすぎても破綻しないAI運用を。毎日AIエージェントで作っている現場目線で、AI導入の設計からご一緒します。まずは相談から——問い合わせは、AIがその場でお応えします。
無料で相談する →




